
One of the best things about being a linguist is that language data is all around us. We interact with it in so many ways every day: listening to podcasts, talking to housemates, and even shopping at grocery stores. It’s easy to start paying closer attention to the language we hear and see, but how can we learn from all this data to better understand how language works? In this post, I’m going to focus on one aspect of this: understanding how other languages work by building a cross-linguistic database.
To do this, I’ll talk about a specific example, a certain kind of agreement with nouns (which I call nominal concord, but I’ll just call it agreement with nouns in this post). The English words this/that change their form based on whether the noun they modify is singular or plural: e.g., these bananas vs. this banana. Other languages do similar things. Many people who have studied a Romance language like Spanish remember that articles and adjectives (among other things) have to match the gender of the noun they modify: e.g., la casa blanca ‘the white house’ vs. el edificio blanco ‘the white building’. How do we figure out the properties of this process so that we can use it to understand language better?
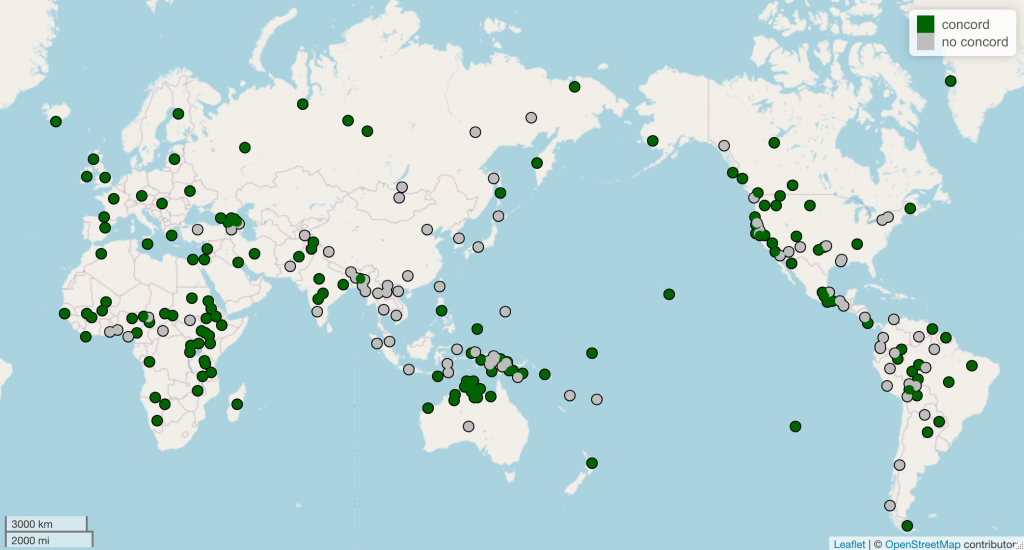
Collecting language examples for the database
Since you’re already swimming in data, you could approach data collection in a very grassroots way. You could travel, taking pictures of language you see in the world, or you could take screenshots of other languages you encounter on blogs or social media. But this can take a long time when you’re looking for data that shows you a specific thing. To develop the database more rigorously, we can turn to more formal sources. We can use grammars, which are book-length reference guides for the properties of languages. Some of these are freely available as books (e.g., Language Science Press, Pacific Linguistics) or PhD dissertations (especially low-resourced languages). Some language data is already compiled and available in online databases (like World Atlas of Language Structures, or Universal Dependencies Corpus) or established corpora (like the Corpus of Contemporary American English, or for something completely different, Estonian corpora available at keelveeb.ee).
There is an important aside here: if we want to understand how language in general works, we have to make sure we’re not looking too closely at one particular language or language family. The languages that most people in North America and Western Europe are familiar with are Indo-European languages. Because these languages are so familiar, there is a reflexive tendency to view their properties as normal or common. To go back to the example of agreement with nouns, we might think that it’s normal for articles and adjectives to agree with noun, because that’s what they do in Spanish. It’s important to remember that we don’t actually know if that’s true! The only way to know for sure is to build a database that does not have overrepresentation of one language or language family.
Selecting a feature/tag set
Now that we’ve talked about sources you can use for your data, the next thing to determine is the set of features or tags that you’ll use to structure the data you collect. Naturally, you will want to focus on features that seem relevant for understanding whatever you’re looking at. If you were looking at agreement with nouns, you could catalog which words agree with nouns and what properties they agree with.
- words: demonstratives (e.g., this, that), cardinal numerals (two, three, four, …), adjectives
- properties: mostly gender, number, or case
So, after collecting your data and storing it (e.g., in a Google Doc), you would also record what words agree with nouns in that language and what properties were relevant for the agreement. There are many features of a language that are likely irrelevant for what you’re looking at. You might need to do some exploratory analysis first to get the lay of the land before you decide on your feature set.
Managing the data and features
I mentioned that you might choose to store the examples you collect in a Google Doc. What about the features? There are several options for managing databases of this type. A non-exhaustive list of options:
- Spreadsheet (e.g., Excel/Sheets): easy to read; allows sorting “by hand”
- CSV: a bit harder to read, but can be easily opened by a spreadsheet program or fed into R or Python for more sophisticated computational or statistical analysis.
- JSON: easier to read with human eyes (in my opinion), easily read with all sorts of programming languages
Saving the data in a format that can be easily read by something like Python is a good investment. You can write scripts to read in all the data you’ve collected and then tabulate any numbers you find relevant. The approach I use is to save each language as an individual JSON file so that updating the database is simple: all I have to do is add the new JSON file(s) to the proper directory. Then I can run the scripts I’ve written to see how the database has changed.
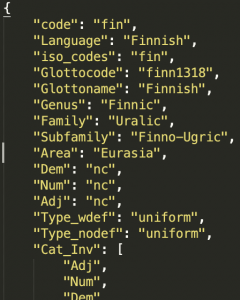
I know I went through this part pretty quickly—I’ll share more about it in a subsequent post!
Once we have enough languages in the database, we can start to extract insights about how different languages do or don’t behave similarly, and through that, we start to learn about language in general. When I built a database like the example I have been discussing in this post, I learned that demonstratives and adjectives are the most likely categories to agree with nouns. In fact, if demonstratives agree with nouns in a language, then it is likely that adjectives will, too. This is just one way in which English turns out to be weird: demonstratives (this/that) agree in English, but adjectives don’t—we don’t say heavies books!
Congratulating yourself
That’s that! As with lots of language work, the most time-intensive part is not really analyzing the results, it’s ensuring that the analysis is based on good data. Collecting good data can take a long time, especially when you’re pulling it from a lot of different languages. So, if you feel compelled to make a database like this one, you might as well start now! A database that would be very useful for both academic and applied contexts would be one that catalogs different word orders that can be used based on the discourse context (e.g., topicalization or focusing) —there are related databases on WALS but they’re less pointed. Any linguists reading this will know that that database could be quite difficult to construct!
A simpler task would be to contribute to an existing database. The Universal Dependencies Corpus is a great example. Right now, the most developed samples in the database are Indo-European languages (and a few other major world languages of Asia). As a result, the Universal Dependencies Corpus is unfortunately still biased!
