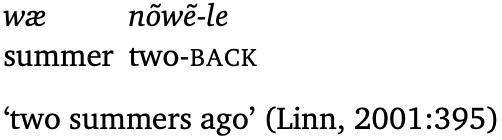When I left the job where I was paid to do linguistic research (among other things), I told myself that I was going to continue to do research (i) as long as I had time for it and (ii) as long as I found it fun (or you know, as long as I wanted to). I anticipated that within 2-5 years, the sun would set on my ability to contribute new research to generative and typological linguistics. I left my academic job just about 2.5 years ago (in May 2019), and I have been working in industry for almost 11 months. As I continue to develop roots in this next phase of my working life, these thoughts have been creeping back into my mind.
Between deciding to leave and actually leaving: anticipatory grieving
Some post-academic folks I speak to seem to have little love lost over their academic research interests, but this was not me. I felt very sad about saying goodbye to those things. In particular, I recall feeling saddest about the changing relationship to Estonian, my primary research language. Leaving my academic post meant saying goodbye to biannual trips to Estonia (for fieldwork and swimming), and it meant less occasion to contact the friends who taught me about their language. I might say that I was worried I would miss Estonian and Estonia so much that I would regret my choice to leave my academic job, but really I think I was just sad that things were going to change.
In the middle: sometimes a source of comfort and purpose and sometimes a distraction
My transition to industry took longer than I expected: 14 months after I relocated to SF (11-12 of those spent actually searching), I got my first industry offer. I have shared this before, but it bears repeating (just so people know): I experienced some of the lowest/darkest moments of my life during that time. Searching for jobs ALWAYS sucks, and so does trying to make a career transition. During this period, doing a little bit of linguistic research would help temper the feeling of purposelessness I often felt. For example, for a few months, I had a weekly reading group with Ruth Kramer, who has been both a dear friend and research advisor essentially since we met in 2008. I spent maybe 20-30% of my “working time” doing linguistics, just because it gave me something to do that I felt like I knew how to do.
There were other times where doing linguistics felt like an indulgence. It felt like it wasn’t quite the thing I was “supposed to do” in order to make myself more competitive for a job. In retrospect, it wasn’t that doing linguistics was EITHER helpful for me or a distraction; it’s that sometimes I needed it, and sometimes I didn’t.
Now completely in industry: I liked it then and I like it still, but I don’t regret my choice
I’m now just over 6 months into my first permanent position at industry, working on problems I find interesting with a team of people I truly enjoy. I did actually have some research output over the last 12 months, and (to my surprise, honestly) I was recently invited to give a colloquium and contribute to another handbook, so I think it’s clear that I’m still doing research at this point. BUT GOODNESS, it’s even harder to make time for it now! After I wrapped up my joint paper with Kyle Mahowald and Dan Jurafsky, I didn’t have any research deadlines, and weeks without doing linguistics passed by before I realized. It’s not that I no longer enjoy it, it’s just that it’s one of many things I enjoy that I have to use time outside of work to enjoy.
This made me think about how I felt before I left: would I miss it? Would I be sad about letting these things go? At this point in my post-academic life, it seems the answer is “No.” That could be because I’ve let go gradually. It could also be because I still haven’t completely let go— I have a handbook chapter that is still set to come out (handbooks are… slow) and I was just asked to contribute to a different handbook (hello, deadline). But I think a large part of it is (i) I’ve had space to move on and (ii) I have a new career that is providing plenty of intellectual stimulation. AGAIN, I must stress that this doesn’t mean I didn’t like it then or don’t like it anymore! I’m still very happy I spent 11 years of my working life dedicated to linguistics teaching and research. I’m also happy about learning to do new language-related things!
Future: What’s actually worth my investment? Can I walk away from unanswered questions?
Since leaving, I have realized that even if I continue to do theoretical/typological research when it is no longer part of my job description, it will not look the same as it did before. There were many research-related activities I did when I was a professor:
- Read theoretical papers: both to stay current and to try to find inspiration when solving a particular puzzle
- Write papers: to share knowledge and proposals in a permanent form
- Present at conferences: to share knowledge and proposals
- Give invited talks: both colloquia and working group talks
- Review articles: if I’m going to keep writing, I should keep reviewing
This is a lot of tasks! And realistically, on a busy research week, I probably can spend about 5 hours on this. Deadlines have become significantly more motivating than they were in the past. I have been able to complete necessary work and not much else. For example, I have had to be more selective about reviewing, and I barely read enough to support my own projects. Forget about staying current!
At some point, it will be time to effectively stop. I have a pipe dream of writing a book and just making it available, published or not. There are too many things I’ve learned—especially about concord—to just leave them in my brain. There are questions that I want to know the answers to, and if I don’t find the answers to these questions, then I don’t get to know what they are (because either nobody else will, or they they won’t tell me if they do). Trying to get all of my knowledge on paper is one way to possibly avoid that, but I also think I will have to leave some of these questions unanswered. I suppose that’s also just part of moving on from jobs more generally— letting go of in-progress work.