
In the past year or so since leaving my academic position and relocating to San Francisco, I have spent my “work time” learning and doing different things. Some of that has been developing my technical skills, and some of it has been continuing the research program I developed while in academia. In particular, nominal concord continues to be an obsession of mine, and I still have unanswered questions that I think nobody will find the answers to if not me. The most satisfying result is when I’m able to marry these two pursuits by using my increased technical skills to improve my research effectiveness. Today, I’m going to introduce the research project I’ve spent the most time with, my typological sample of nominal concord, aka Conctypo.
I’ve debated whether to kick off this series from the very beginning, but I decided instead to start where I am right now. I’ll dig into the past in some subsequent posts.
What is nominal concord and what is Conctypo?
If you’ve studied a European language before, you’ve probably encountered the phenomenon that I (and others) call nominal concord. For example, in the Spanish phrases la casa blanca ‘the white house’ and el edificio blanco ‘the white building’, the words for ‘the’ (la/el) and ‘white’ (blanca/blanco) change their form based on the noun that they modify. In this instance, it’s because the noun casa ‘house’ is feminine and the noun edificio ‘building’ is masculine. This is an example of nominal concord.

More technically, nominal concord is the agreement process in language whereby modifiers of a noun (eg, adjectives, numerals, or demonstratives) must match the noun they modify in particular features (eg, gender, number, or case). Nominal concord is a well-known process in linguistics, perhaps due to the fact that it is widespread in Indo-European languages. But it exists outside of the range of Indo-European languages: it is found on all 6 inhabited continents (sorry, Antarctica, but you don’t count as inhabited).
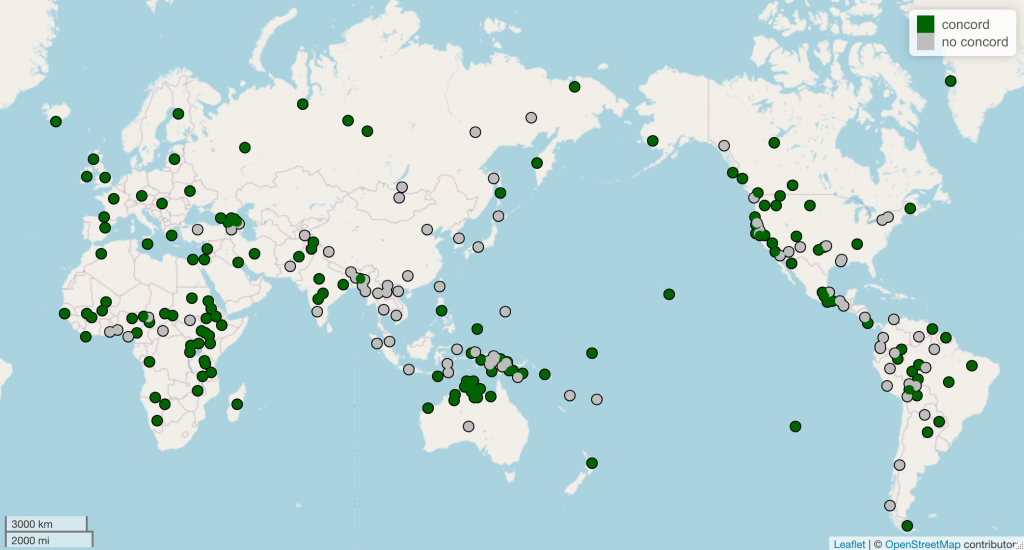
Conctypo is a typological sample of nominal concord in the world’s languages. As of this writing, I (with the help of research assistants while I was at OU) have collected data on 244 languages. The first time I presented about the project was at the LSA meeting in 2019. The paper and entire data set (including only 174 languages for better genetic/geographic balance) is available in the SHAREOK archive here: A typological perspective on nominal concord. Since then, I have stopped managing the data with spreadsheets and now store the information in JSON files. All that I have to do to update the database is add the JSON files for the new languages and run the Python scripts I’ve written to pull relevant numbers. But more on that in a later post!
Why build this typological database?
While there are many broad tendencies in language structure—go tool around WALS if you never have—languages also have plenty of idiosyncratic properties. When devising models of language structure, a reasonable approach (to my mind) would be to use common properties as the foundations of the theory. In order to build a theory of nominal concord, we would need an understanding of what the common properties of nominal concord are. That’s where Conctypo comes in— the cross-linguistic sample can tell us what is common in concord systems. In turn, when looking at the concord system of a particular language, we can correctly identify idiosyncratic properties as idiosyncratic (instead of mistaking them for plausibly general properties of concord).
To put a finer point on this, let me discuss Indo-European briefly. Often, when a researcher brings up nominal concord, they use data from an Indo-European language to highlight its behavior. Concord systems in other languages are compared to Indo-European systems, with the implicit assumption that Indo-European systems are normal or common. Yet without a cross-linguistic understanding of concord systems, we can’t be sure this is true! Concord in Indo-European languages is robust and regular; commonly, gender and number are represented on nearly every word modifying a noun. But concord in the world’s languages could be more sporadic. It could involve, for example, number on some words and gender on other words.
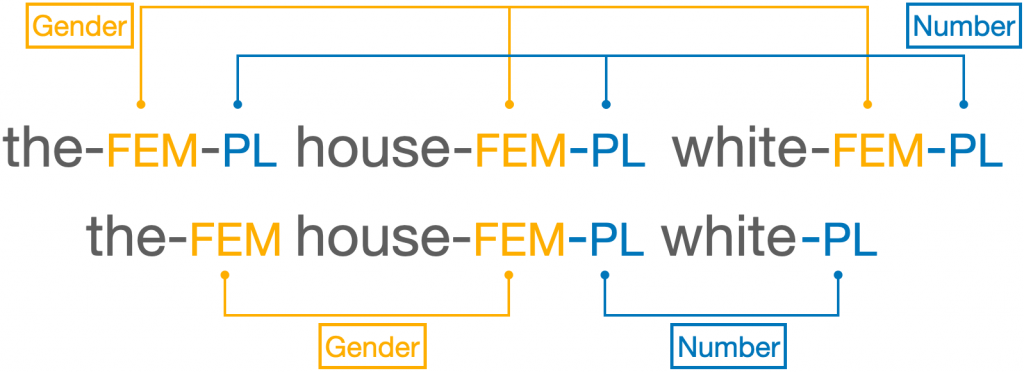
In this world, Indo-European concord would be perhaps overzealous. The only way to know—well, the only way to feel more assured—is to go to the data.
At the time I started gathering data, I knew of no other typological investigation of nominal concord. Thus, if I wanted to know the answers to these questions, I had to find them myself. After about a year and a half, I found the work of Ranko Matasović and İsa Kerem Bayırlı, who have collected their own concord or concord-related typological samples. We do not all document the same properties, though, so the more, the merrier!
How did we collect the data?
We look for linguistic examples on three different kinds of words:
- Demonstratives: words like this/these or that/those
- Cardinal numerals greater than ‘one’: number words like two, three, or seven. We specifically avoid ordinal numerals like second, third, or seventh as these often behave like adjectives. We also avoid one because it shows idiosyncratic behaviors in some languages—the goal was to try as much as possible to look at numerals as a distinct category.
- Adjectives: words like green, tall, old, etc. This can get tricky as some languages lack a clearly defined adjective class.
To find the examples needed, we look in published sources, including PhD dissertations. Ideally, this would be a grammar, i.e., a reference guide to the linguistic properties of the language. Failing a suitable grammar, we will use other types of writing (ideally published, but for some languages, the only available material may be unpublished). We look through the grammar to find suitable attested examples, where “suitable” means something like If the language had concord, we would be able to see it in this example. I take pictures, take screenshots, or copy the text of the example and save it in a Google Doc for archival purposes (and in case I ever want to check my work).

Once I have finished documenting all three word classes, I can update the database. I wrote a program in Python that asks me the requisite questions and then creates a properly formatted JSON file and saves it in the proper place (more on this program later!).
And the work continues…
My work on this project continues in the form of data collection, computational streamlining, and pursuing theoretical implications. Until next time!
Very cool! Sadly, none of the languages I’ve studied professionally (Southern Pomo, Northeastern Pomo, Panim) have nominal concord 🙁
Well, can’t win ’em all, I guess. Thanks for sharing!